
使用现代 AI 模型——例如 GPT、DeepSeek、Mistral——将网站翻译自动化提升到了一个全新的水平。这对于 Tilda 网站尤其重要,因为 Tilda 网站“开箱即用”不支持多语言,而 Google、Yandex 等的自动翻译需要手动更正,这是一个非常耗时且容易出错的过程,并且无法为网站的 SEO 优化提供所需的结果,因为它们在浏览器加载后才翻译网站。
Multify 服务不仅仅通过对 AI 模型进行单一请求来翻译文本,它使用一个完整的系统——考虑到上下文和图架构,这有助于保持整个网站文本的连贯性。接下来——这一切是如何运作的。
🔄 为什么上下文很重要
当网站上的文本被翻译时,特别是很小的一部分(例如,菜单项、按钮或页脚中的一行),孤立的方法会产生不准确的结果。模型可能不理解该短语与什么相关,它如何与其余元素协调,并选择错误的翻译。
为了避免这种情况,Multify 不仅将要翻译的文本本身传递给模型,还传递其周围环境:
[ 前面的文本 ]
[ 要翻译的文本 ]
[ 后面的文本 ]这种方法有助于模型将片段视为一个连贯整体的一部分,而不是一个零散的回复。
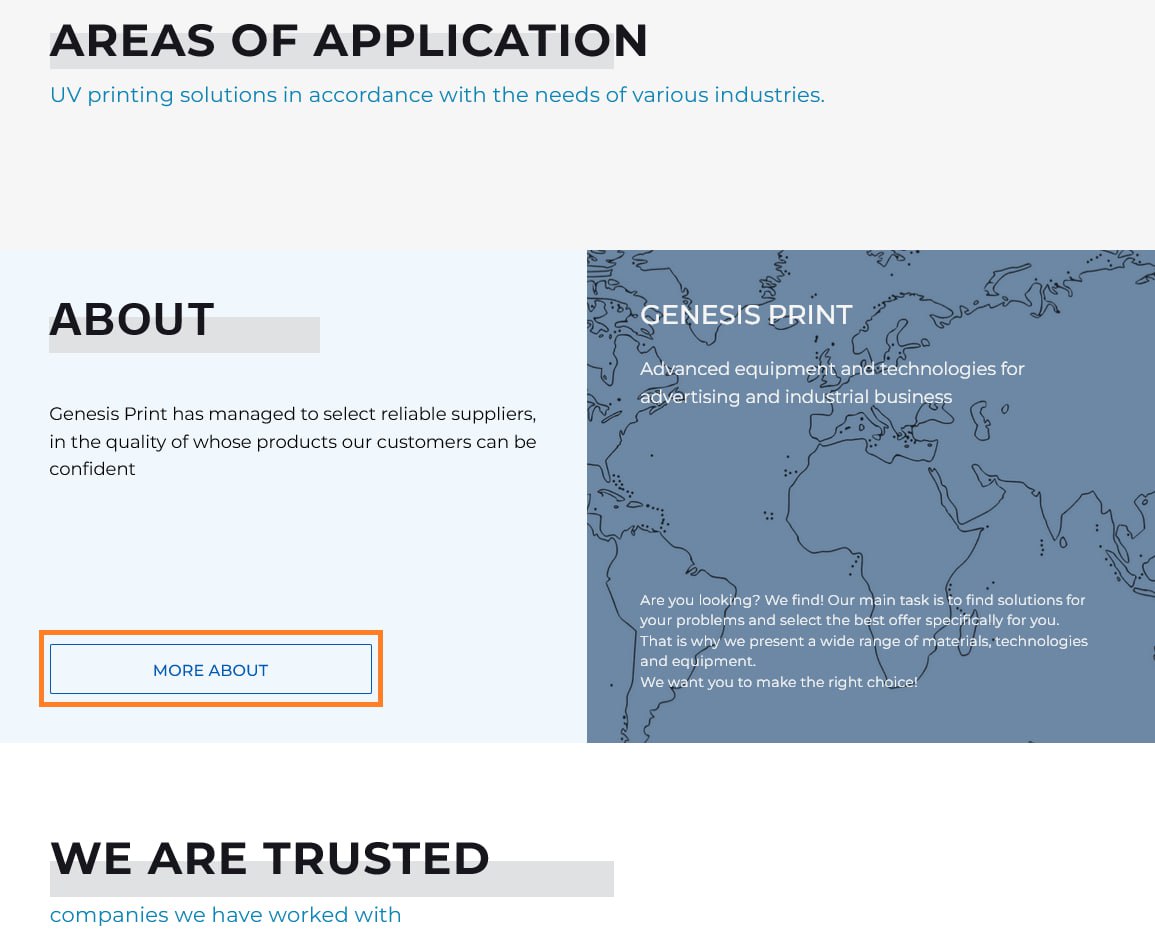
📍示例
在此网站上,模型在翻译 “more about” 按钮时会考虑上方和下方区块的上下文:
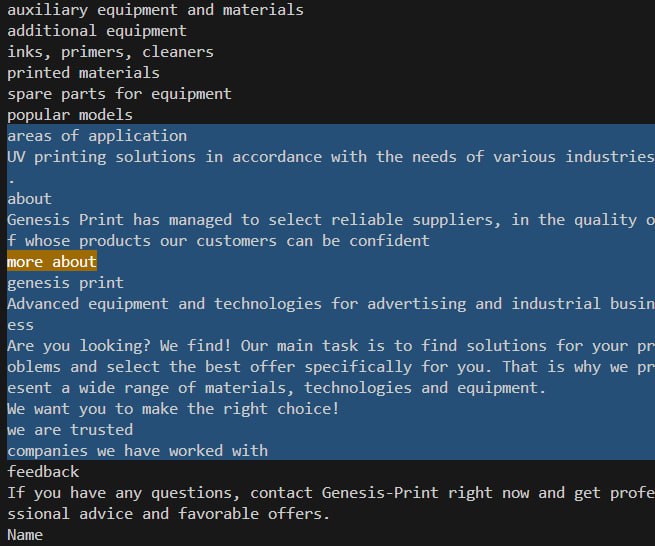
在下面的代码中,突出显示了 “more about” 按钮周围的上下文:
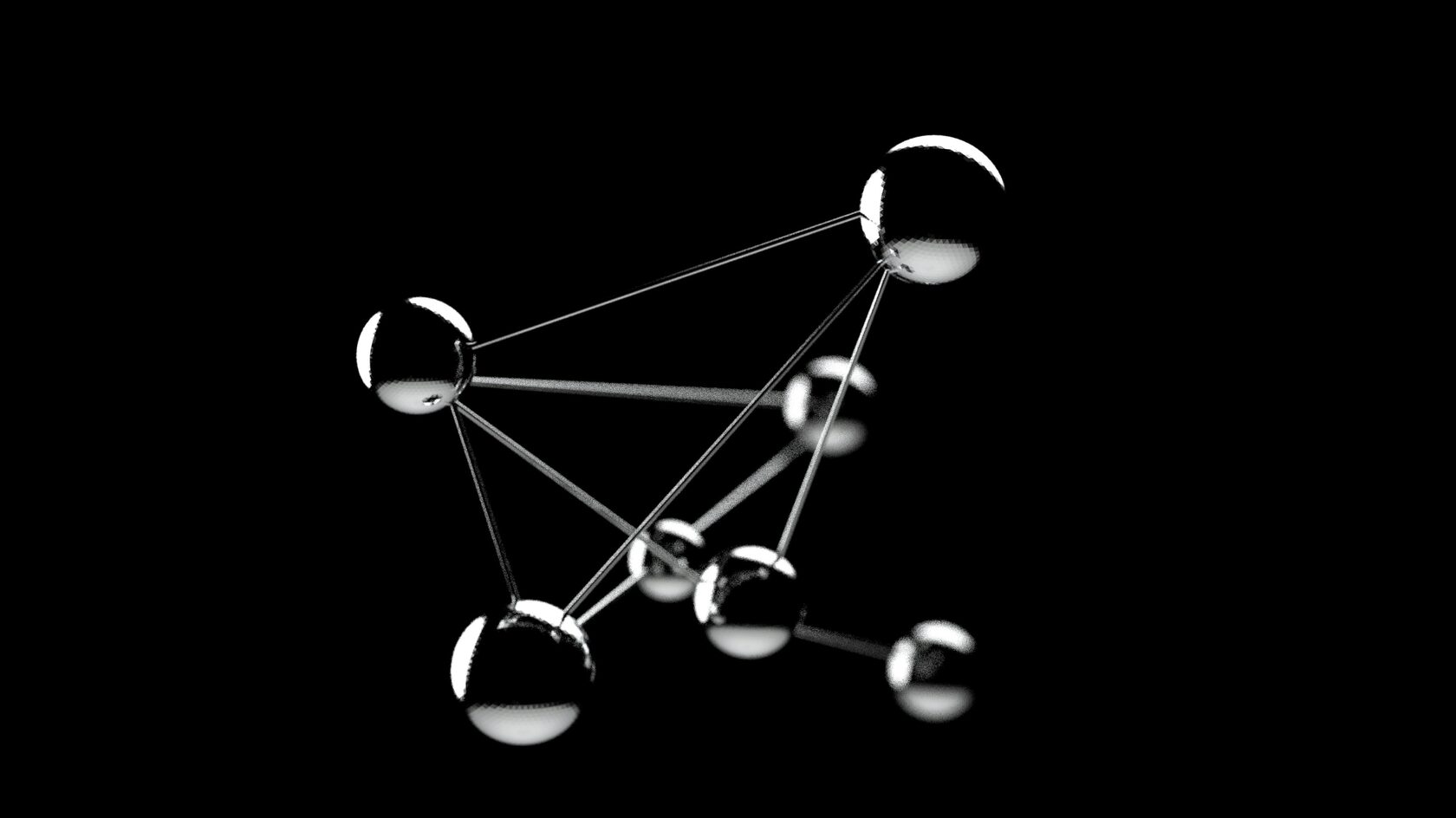
➰ 图形结构:上下文是如何形成的
为了更准确地确定片段的上下文,Multify 将整个文档(网页)分解为块,并从中形成一个双向图。这意味着:
- 每个文本元素都知道它旁边有哪些块。
- 如果页面中间添加了一个新片段,可以自动确定其“邻近区域”。
- 模型不仅接收片段本身,还接收与其逻辑相关的块——即使它们之前已被翻译。
这种方法有助于保持语义完整性和语法一致性——例如,正确的格、时态和文体一致性。
💯 为什么它能更好地工作?
翻译中的上下文是质量的关键。尤其体现在以下方面:
- 复杂的名称和技术术语
- 没有动词的短语(例如,“For home”,“To warehouse”)
- 依赖于环境的重复元素
在不理解上下文的情况下,LLM可能会生成“形式上正确”但听起来不自然或不准确的翻译。通过图谱和正确的环境传递,Multify避免了这些错误。
🔝 对SEO有什么区别?
除了AI模型翻译的质量和准确性之外,多语言网站实现的技术部分也存在显著差异,这严重影响了搜索结果。这是因为通过谷歌翻译或Yandex翻译在浏览器中加载页面后进行的网站翻译,这些翻译是在客户端执行的,不利于SEO优化。
搜索引擎不会索引通过未经人工编辑的自动化工具创建的翻译内容,因为它被视为自动生成的内容。
搜索引擎不会索引通过未经人工编辑的自动化工具创建的翻译内容,因为它被视为自动生成的内容。
“Google 不会索引通过 Google 翻译创建的翻译内容,这限制了您的网站在国际市场上的可见性。”
→ 来源:Auris AI [我的翻译]
因此,为了多语言网站的有效 SEO 优化,建议使用服务器端解决方案,这些解决方案允许搜索引擎访问翻译内容。
🚀 Claude — 最佳翻译质量
Multify 现在使用 Claude 3.5 Haiku——此 LLM 在独联体国家语言(哈萨克语、乌兹别克语、乌克兰语、罗马尼亚语、阿塞拜疆语、吉尔吉斯语、亚美尼亚语、塔吉克语、白俄罗斯语、土库曼语)的翻译质量方面表现最佳。
尽管Claude的成本高于其他AI模型,但凭借其专有架构和无限服务器的使用,Multify提供:
💸 具有竞争力的价格
🥇 Tilda解决方案中的最高质量
🌐 支持复杂语言和区域变体
🎯 总结:一切如何协同工作
- 页面被分解为逻辑块
- 每个块都有自己的上下文——之前和之后的文本
- 形成图谱,以便在更新时快速确定邻近区域
- 模型获取所需的上下文并提供连贯、准确的翻译
结果您将获得:
✅ 多语言网站无重复
✅ 自然流畅的翻译
✅ 改进的SEO标签和元标签
✅ 灵活性和可扩展性,无需手动操作
✅ 自然流畅的翻译
✅ 改进的SEO标签和元标签
✅ 灵活性和可扩展性,无需手动操作
